
Big Data in Railroad Maintenance Planning: Evolving Science, Evolving Applications
By Jeff Tuzik

The concept of big data is something the railroad industry has been aware of for many years. The Federal Railroad Administration, for example, has been involved in research and development projects involving big data, neural networks and machine learning since as early as 2002. The prevalence and proliferation of automated inspection technologies in the past decade brought the concept further into the mainstream, though the discussion remained largely theoretical. Even as the volume of collected data has increased throughout the industry, questions of how best to process, correlate, and even view that data were generally unanswered. More recently, the discussion has begun to shift from the realm of theory to that of practical application. This shift is driven by a combination of factors, but is primarily due to the prevalence of automated inspection technologies, increasingly large and complex databases, and advances in machine learning techniques.
The rapidly changing nature of the big data discussion in the railroad industry was shown in the Big Data in Railroad Maintenance Planning conference, produced by Allan Zarembski, Director of Railway Engineering and Safety at the University of Delaware, and hosted by the university. The first conference, in 2014, primarily dealt with the challenges and opportunities presented by big data, as well as a number of fledgling or upcoming projects. “At [the 2014 conference] we saw data analysis techniques that were more mature than the available data and applications,” said David Staplin, former Chief Engineer – Track at Amtrak and Chairman of the Railroad Advisory Board at the University of Delaware. That’s beginning to change. The third iteration of the conference, which was held in December 2016, showcased advances in the techniques and mathematics behind data processing, as well as updates to projects throughout the industry that seek to leverage the power of big data in various ways.
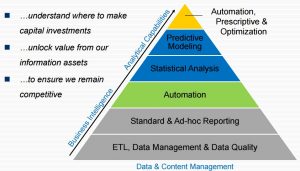
Regardless of the application, the projects that involve big data in the railroad industry can generally be broken down into three phases: data collection; data processing; and data reporting and visualization. Part of the difficulty in applying the kind of advanced analytics that big data makes possible, is that each phase can be a bottleneck. “It doesn’t matter how good your analytics are if you have concerns about the accuracy and reliability of your data,” said Leo Kreisel, Director of Track Testing at CSX Transportation. Similarly, the difference between a theoretically, versus a practically, useful deliverable can come down to how easy it is to interpret and make decisions based on the output data. So the challenge that applied big data presents in the industry is not only in optimizing each phase, but in fitting each phase together. This is made even more challenging by the fact that railroads, researchers and suppliers throughout the industry use a number of bespoke solutions to collect, process and report on data, said Srini Manchikanti, Technical Director, Enterprise Information Architecture at CSX Transportation. “None of the hardware or software we use is off-the-shelf, so every step along the way is a development effort,” he said.
Not every project that leverages big data actually requires additional data collection, however. “Railroads are already sitting on a lot of data, and that data can be mined for correlations and patterns,” said Joe Palese, Senior Director, Engineering Analysis and Technology at Harsco Rail. The wealth of data that railroads collect and store as part of their regular inspection practices means that there is a vast potential resource available for mining and information discovery, particularly if it can be shared.
“The development of industry-wide shared databases is critical to getting the most out of big data,” added Gary Carr, Chief of Track Research at the Federal Railroad Administration. Some industry-wide data already is shared, such as in the Transportation Technology Center Inc.’s InteRRIS Central Detector Database. A number of universities and researchers have access to industry datasets in support of their research – but these are the exception, not the rule, and represent only a small fraction of existing data, Allan Zarembski noted. Despite the difficult legal and technological hurdles, several presenters echoed the sentiment that the industry stands to benefit greatly by sharing more data.
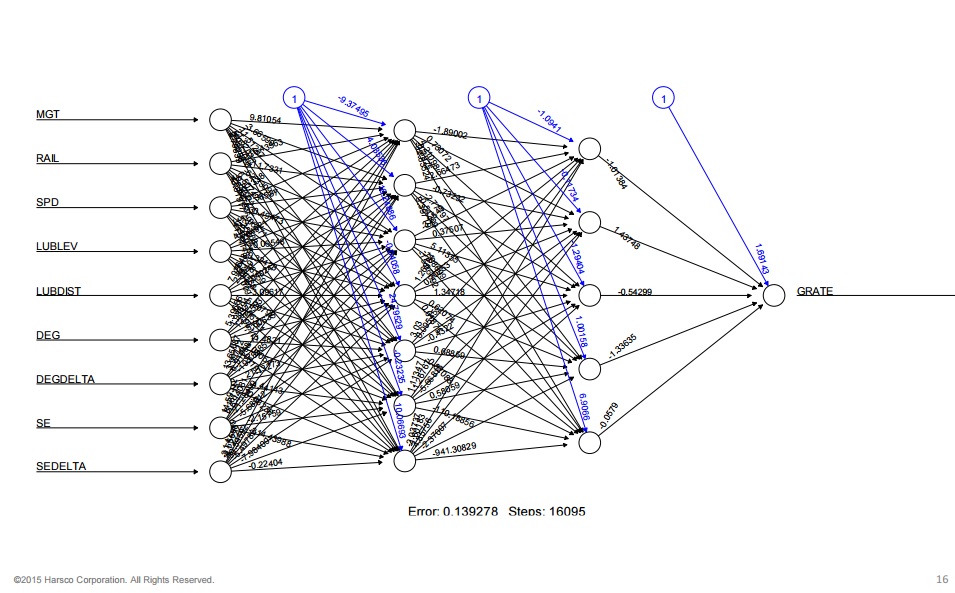
Regardless of where the data come from, the convergence, correlation and processing of that data is the next hurdle to get over. This is an area in which machine learning has become an increasingly common and increasingly powerful tool to employ. A number of railroads like Canadian National and CSX and suppliers like Harsco Rail and ENSCO Rail are currently working on research and development projects based on machine learning. A recent Harsco project explored the use of deep neural network architecture (a type of artificial neural network used in certain machine learning applications) to predict rail wear – specifically, the rate of gauge wear. For the project, nine inputs were selected to train the deep neural network (DNN):
- Annual MGT
- Rail section
- Speed
- Lubricated vs unlubricated
- Distance to lubricator
- Degree of curvature
- Delta degree of curvature from design spec
- Superelevation
- Delta superelevation from design spec
Several iterations of the DNN were trialed with a varying number of layers, Joe Palese said. The outputs, or predicted gauge wear rates, were then compared to actual wear data. The results showed that a two-layer iteration performed best, with an actual-to-predicted R2 of 87.5 percent (See: relevance of R2 in statistical analysis). “The results gave us better accuracy than traditional prediction methods,” he said. This project used a tremendous amount of existing data in order to achieve its promising results, but it functions largely as a proof-of-concept. When it comes to machine learning, Palese said, “we’re just now getting to the point where these kinds of techniques have practical applications in the industry.”
But it’s not all theoretical. One of the ways big data is leveraged in the industry today is in asset management and the development of common, single asset-performance indicators, such as the track quality index (TQI) and track condition index (TCI). These indices represent a convergence of multiple disparate data sets, such as those taken by various measurement devices on a track geometry car, which are calculated with weighted coefficients based on a number of parameters, such as geometry exception level or severity. “The TQI allows you to collapse a lot of information down to one value, and one decision,” said Jackie van der Westhuizen, Business Director of Rail and Transit Asset Management at ENSCO, Inc. The TQI is also a good example of a practical reporting and visualization component of a big-data-driven project.
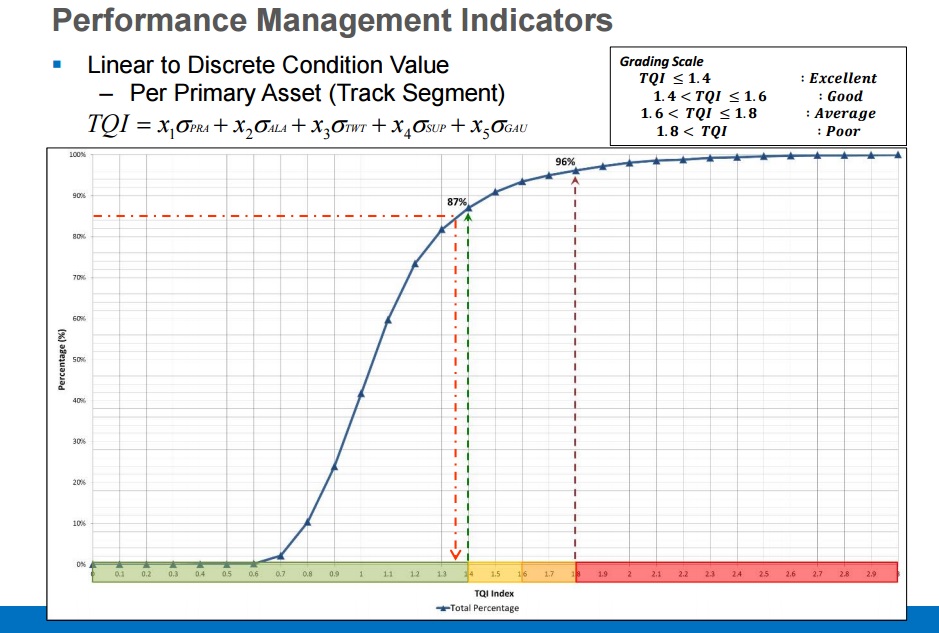
“Different stakeholders want to look at data in different ways. Chief executives may look at the segment perspective, while maintenance looks at the asset perspective,” Van Der Westhuizen said. Sometimes this is a simple matter of moving up or down a hierarchical view, but sometimes it means repackaging the data in a different format, he said. Big data, as it applies to asset management, has become a particularly salient topic in light of the newly adopted State of Good Repair directives governing rail transit. More than ever, organizations will be driven to combine and correlate their asset health data. Though this is a difficult process, it paves the way for exploiting big data that might otherwise go underutilized.
While the discussion on big data in the railroad industry has evolved in the past several years, it’s clear to see that there’s a long way to go. “The use of big data solutions in railroad infrastructure is in its infancy,” said CSX’s Leo Keisel. The Big Data conference provides an interesting snapshot of the state of the art in the industry, particularly in how advances are made concurrently in the fields of data collection, data analysis, and data visualization. Each of these advances moves the discussion forward in its own field but the biggest breakthroughs and the practical applications seem to be just around the corner, awaiting the convergence of all aspects of the big data environment.

Jeff Tuzik is Managing Editor of Interface Journal.